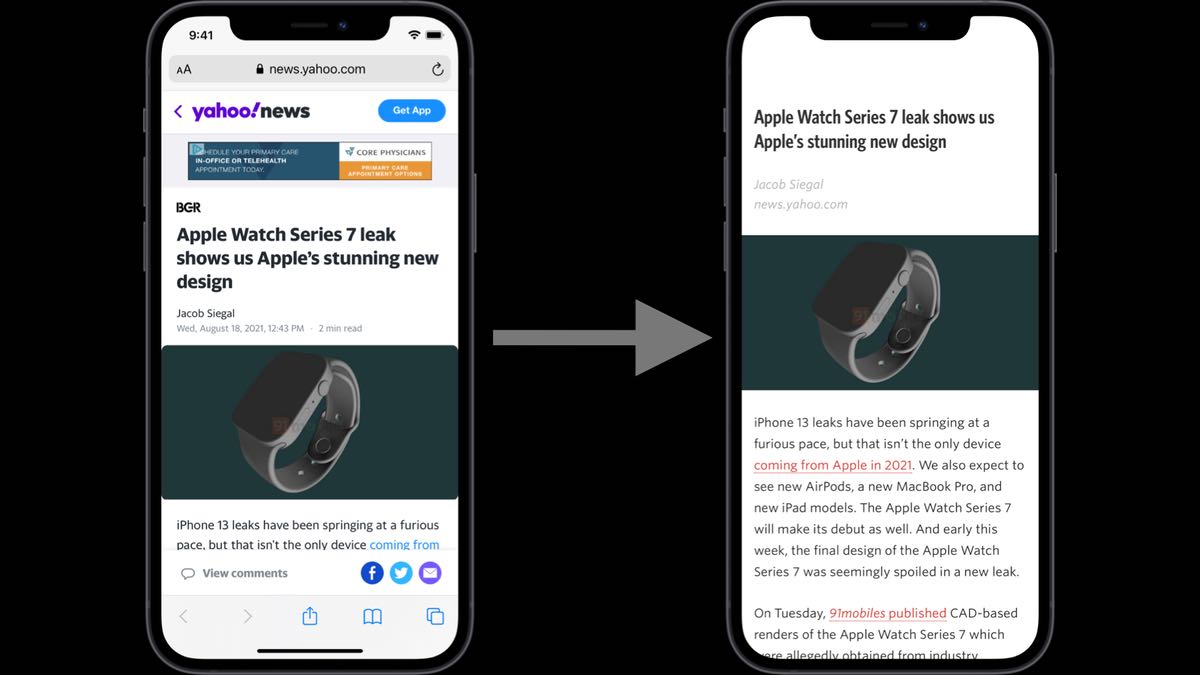
I am excited to announce the availability of the Webpage Text API, a cloud service that lets an app or web service request the HTML for the content of a webpage without the junk (chrome, navigation, ads, and scripts) that tends to clutter modern webpages.
The Webpage Text API has been powering the webpage text feature of Unread since I released Unread 2 in February 2020. It is perfect for RSS readers, read later services, browser extensions, newsbots, and other applications where the user wants the content of the webpage without the cruft.
I started developing the Webpage Text API for Unread in 2018, before Mercury Parser went open source. At the time Unread had webpage text retrieval capabilities powered by Readability.js. That worked well, but I needed the ability to cache webpage text and associated images ahead of time. It was impractical to generate webpage text for thousands of articles at a time on-device, so I researched server-based options.
At that time Mercury Reader provided an API and generously made it available for free. However their terms of service would not allow Unread to aggressively cache webpage text for articles ahead of time. The Mercury Parser source code had not yet been made public.
I looked into commercial options, but none fit my needs. So I started writing my own server-based system. I started by incorporating the heuristics used by Readability.js. I then added test cases from hundreds of different websites to improve the webpage text quality.
After Mercury Parser went open source, I evaluated whether it would be more suitable for generating webpage text for Unread. I discovered that I got higher quality results from my own Webpage Text API than I would from Mercury Parser. This inspired me to continue improving the Webpage Text API, and to now offer it as a commercial product.
Check out this demo to get a sense for the quality of results. To get started with the Webpage Text API, contact me at sales@goldenhillsoftware.com.